Virtuoso Crawler Guide for populating Virtuoso Quad Store using ATOM feed
What?
This Guide demonstrates populating the Virtuoso Quad Store using ATOM feed.
Why?
Populating the Virtuoso Quad Store can be done in different ways Virtuoso supports. The Conductor -> Content Import UI offers plenty of options, one of which is the XPath expression for crawling RDF resources URLs and this feature is a powerful and easy-to-use for managing the Quad Store.
How?
To populate the Virtuoso Quad Store, in this Guide we will use a XPAth expression for the URLs of the RDF resources references in a given ATOM feed. For ex. this one of the "National Bibliography" Store.Sample Scenario
- Go to http://cname/conductor
- Enter dba credentials
- Go to Web Application Server -> Content Management -> Content Imports:
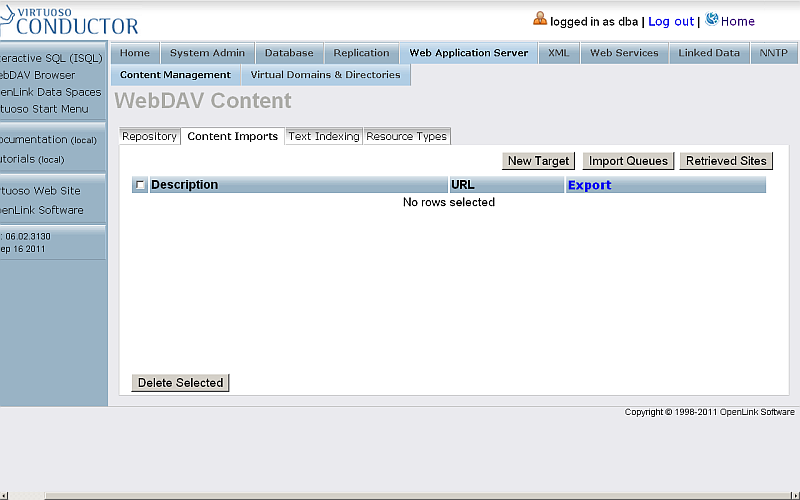
- Click "New Target":
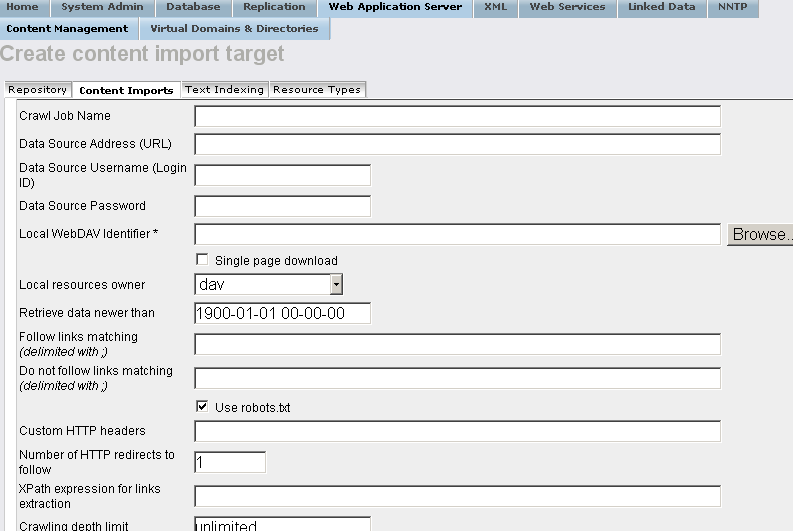
- In the presented form specify respectively:
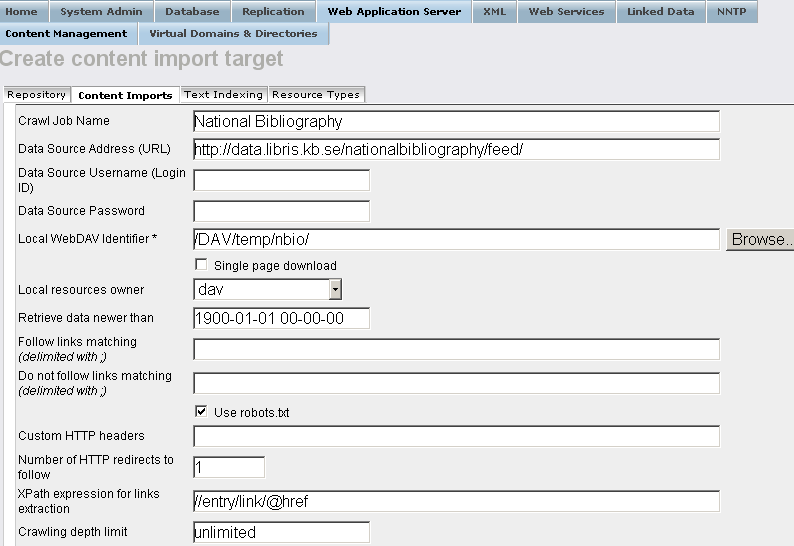
- Crawl Job Name: for ex. National Bibliography ;
-
Data Source Address (URL): for ex.
http://data.libris.kb.se/nationalbibliography/feed/ ;
- Note: the entered URL will be the graph URI for storing the imported RDF data. You can also set it explicitly by entering another graph URI in the "If Graph IRI is unassigned use this Data Source URL:" option.
-
Local WebDAV Identifier : for ex.
/DAV/temp/nbio/
-
XPath expression for links extraction:
//entry/link/@href
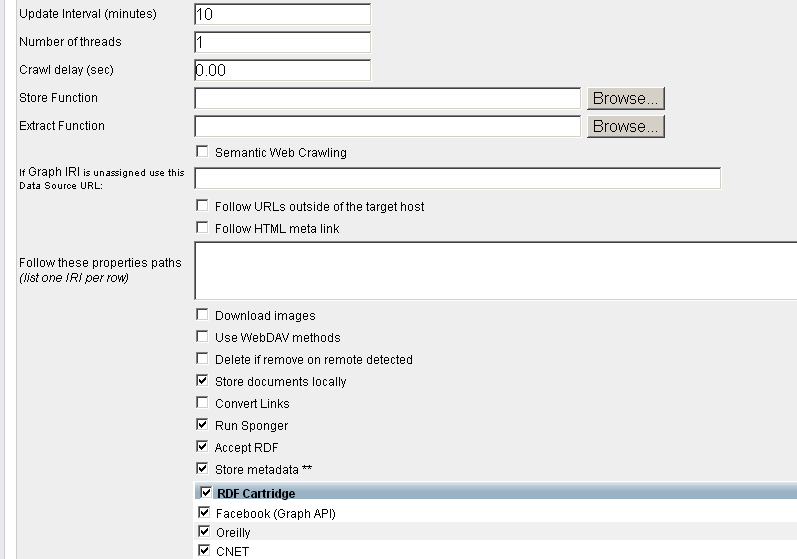
- Update Interval (minutes): for ex. 10 ;
- Run Sponger: hatch this check-box ;
- Accept RDF: hatch this check-box ;
- Store metadata: hatch this check-box ;
-
RDF Cartridge: hatch this check-box and specify what cartridges will be used:
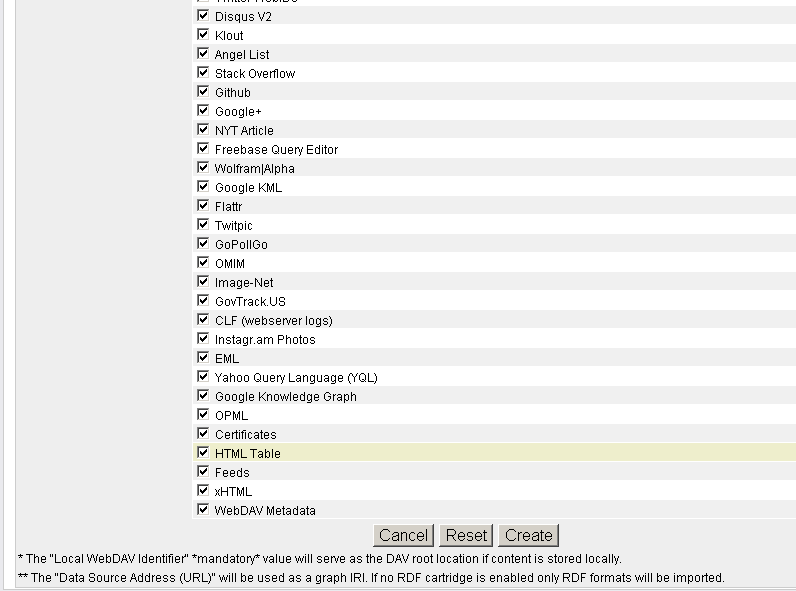
- Click "Create":
- The new created target should be displayed in the list of available Targets:
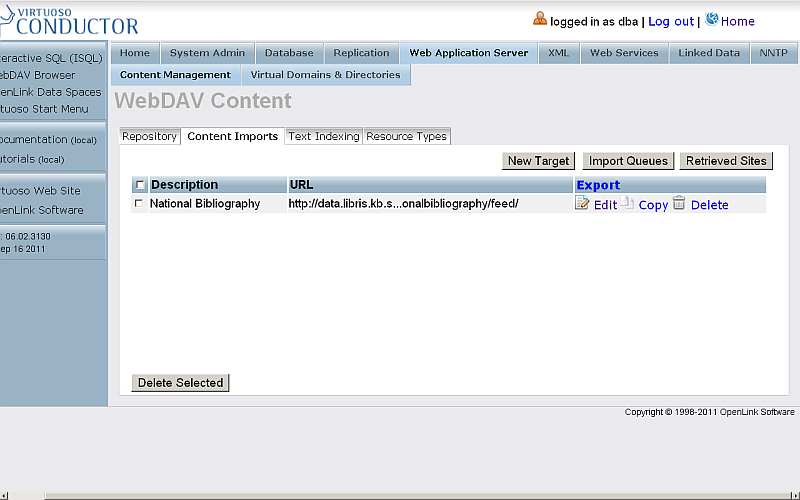
- Click "Import Queues":

- Click for "National Bibliography" target the "Run" link from the very-right "Action" column:
- Should be presented list of Top pending URLs:
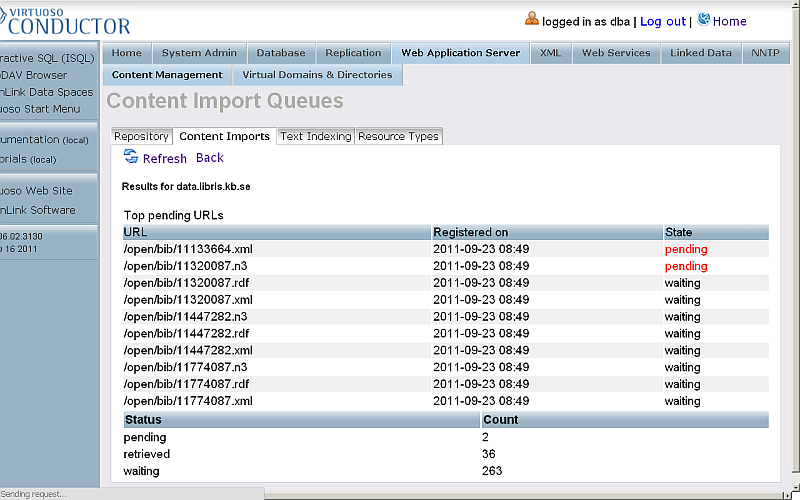
- Finally when the import is finished, should be shown the total URLs that were processed:
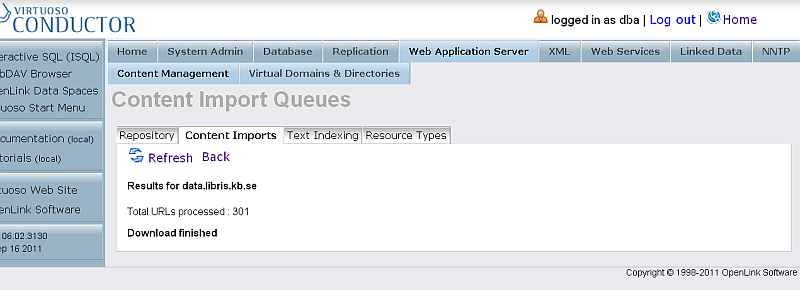
- Click "Back"

- Click "Retrieved Sites".

- Out target should be presented in the list of available retrieved sites. From here you could manage the retrieved URLs by editing the imported URLs or exporting to External/Internal WebDAV destination. Click for ex. the "Edit" link of the very-right "Action" column for our retrieved site.
- Should be presented all downloaded URLs of RDF resources referenced in our initial ATOM feed.
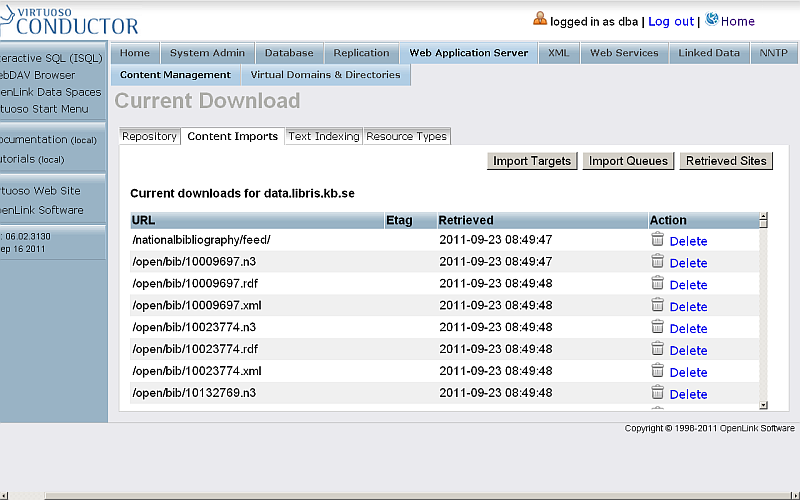
- To view the imported RDF data, go to http://cname/sparql and enter a simple query for ex.:
SELECT * FROM <http://data.libris.kb.se/nationalbibliography/feed/> WHERE { ?s ?p ?o }
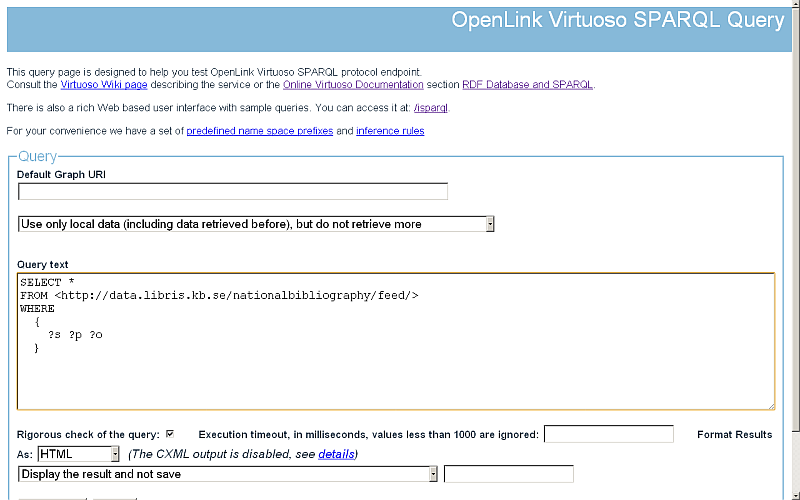
- Click "Run Query".
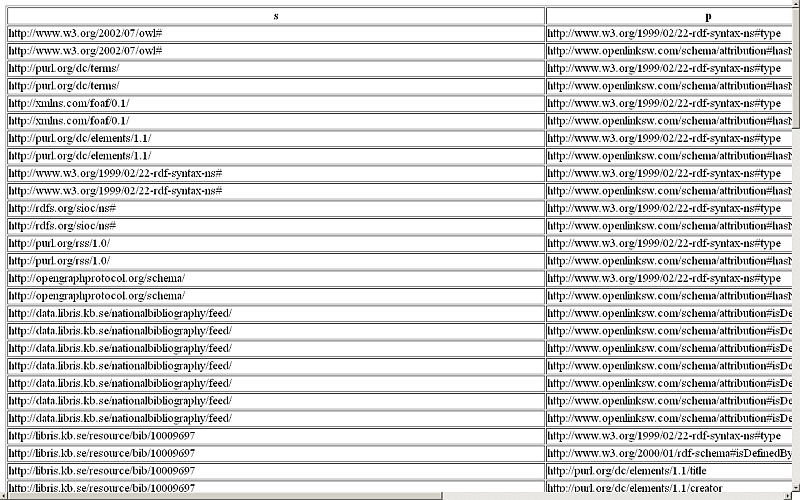
- The imported RDF data triples should be shown:
Related
- Setting up a Content Crawler Job to Add RDF Data to the Quad Store
- Setting up a Content Crawler Job to Retrieve Sitemaps (when the source includes RDFa)
- Setting up a Content Crawler Job to Retrieve Semantic Sitemaps (a variation of the standard sitemap)
- Setting up a Content Crawler Job to Retrieve Content from Specific Directories
- Setting up a Content Crawler Job to Retrieve Content from SPARQL endpoint
- Virtuoso XPATH Implementation and SQL
- Collection examples of live ATOM and OAI-PMH feeds.