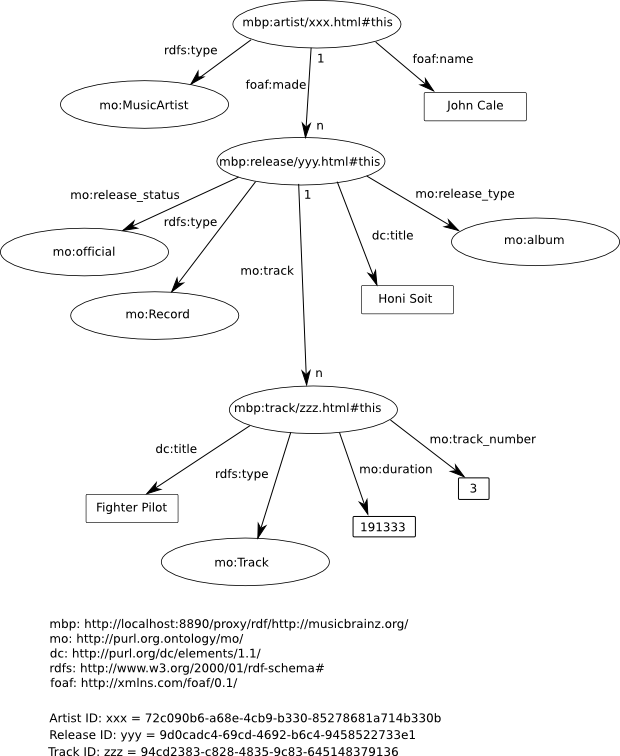
 An example conceptual data model expressed in RDF/RDFS
relating artists, albums and tracks
An example conceptual data model expressed in RDF/RDFS
relating artists, albums and tracksTaken from Exploiting the RDF-based Linked Data Web using .NET via LINQ
The aim of the Semantic Web vision was always about a Web of interlinked structured data items (entities). Unfortunately the popularity of one type of data item (the document) has inadvertently clouded the broader vision. In recent times, a 'Linked Data' meme has emerged from the Semantic Web community that provides focus insight into the critical transition from a Web comprised solely of 'Linked Documents' to one that also includes other types of 'Linked Data Entities'.
The new Semantic Web community focus on Linked Data is essentially about Web based open data access and integration without the infrastructural limitations of yore. That said, this long-term vision isn't immune to other inflections occurring across the broader industry such as moving data interaction away from the logical data model level to a higher conceptual level. This paper examines the applicability of the emerging Linked Data meme to new frontier of conceptual model oriented data access and integration across heterogeneous data sources and platforms.
It should be noted that exposing structured data using Web Services and the move to conceptual data model oriented data access are themes also echoed in Microsoft's ADO.NET Data Services product offerings, and the earlier efforts from NeXT? Computer in the form of Enterprise Object Frameworks (EOF). A brief comparison is included that compares and contrasts Microsoft's initiatives with those of the standards based Linked Data.
It is common for software systems to be centered on data models to represent aspects of their target problem space. Data models can describe the relevant concepts and data structures from an application domain and encode knowledge that is useful to drive an application's behavior.
In today's database driven applications, three levels of data model are typically used - physical, logical (e.g. relational) and conceptual (domain):
Of the aforementioned model types, the logical model tends to be the main focus of database applications, due in the main to the pervasiveness of SQL based RDBMS applications. However, it brings with it several weaknesses such as:
In traditional data-centric applications, whatever the data access technology used (JDBC, ODBC etc), SQL has remained the common query language throughout. Because SQL expresses queries in terms of tables and views, it targets the logical schema. Although SQL and the logical schema insulate applications from changes to the physical layer, for instance the addition of a database index, logical schemas based on the relational model suffer from a fundamental weakness when faced with normalized schemas. Although normalization is desirable to protect against data anomalies, it typically involves decomposing an unnormalized table into two or more tables that, were they to be combined (joined), would convey exactly the same information as the original table. As a result normalization fragments the data model. Entities and their attributes from the original problem domain may be split across several tables when represented in the normalized logical schema. Consequently operations that are natural within the conceptual model, such as navigation between objects, are not straightforward within the logical model. Applications must use SQL to perform relational joins, possibly over several tables, and logic to reconstitute rows from these tables into a higher level conceptual entity of the problem space. The recurring need for this type of transformation in applications based on a relational data model has been termed the 'impedance mismatch'. A move to applications written to target the conceptual level is highly desirable as it removes the impedance mismatch and isolates applications from changes to the logical data model.
Typically, when developing database applications, first the conceptual model of the model is developed (e.g. using entity-relationship modeling), but for actual implementation it is transformed into a normalized logical model. Once the transformation is completed, the conceptual structure and intent of the original model become obscured. For instance, in the logical model, database keys (primary and foreign) signify some form of relationship, but there are no explicit semantics to substantiate these relationships bar referential integrity enforcement. Thus, the conceptual and the logical models ultimately diverge. Further, when the physical model is derived from the logical model further semantics are lost, resulting in the domain model semantics becoming implicit rather than explicit, and fragmented across the schema, business rules and application logic - which is why it is necessary for a majority of current applications to be aware of the logical data model beforehand, or infer it, imperfectly, from the system tables that make up a limited data dictionary.
Using the popular relational database model as an example, the problem domain is defined in terms of relational tables and columns, requiring the use of SQL to navigate the model, thereby exposing application developers and users to the specifics of a particular vendor's data management technology. Thus, applications dealing with data sources across heterogeneous databases must confront the challenges associated with SQL dialect variety and inherent structural disparity of database schemas. As a result of this historic reality, achieving interoperability between disparate systems within or between enterprises has been the bane of IS/IT departments for many years.
Exponential growth of disparate user generated data courtesy of the Internet and the Web has unveiled the imminence of 'information overload' which can only be alleviated via increased capabilities in the data access and data integration realms. Thus there has been a growing recognition in the industry of conceptual model virtues as they relate to data-centric applications, that extends beyond the design phase, up to a framework for human and agent (program) level interaction.
As its name suggests, a key aim of the Semantic Web vision, as expressed by Tim Berners-Lee, is to attach more formal structure to current Web content. Thus, by annotating opaque documents with ontology based metadata and/or publishing structured data from the outset, the Web becomes a much richer collective, endowed with organic capabilities that enable and encourage explicit semantic enrichment courtesy of the activities of all Web users. Central to increasing the 'linked data' within the web is the ability to express and convey conceptual models, a facility which the Web lacked initially but which is now possible via Semantic Web realm technologies. Advantages of these new Web capabilities include:
In turn these advantages are either shaping recent trends in Web use or enabling new forms of interaction:
Given the clear benefits conceptual models provide, how are conceptual models realized via RDF?
As one of the cornerstone technologies of the Semantic Web, the Resource Description Framework (RDF) was designed from the ground up to address the issue of formally describing Web resources. It provides the means (data model, markup, and byte stream serialization formats) for effectively describing Web resources via their properties using statements based on the subject, predicate and object pattern common to basic sentence structure. RDF does not mandate the use of any particular properties or element names. The creator of an RDF statement (a record in the RDF model) can choose which properties they wish to use. However, the real power of RDF manifests itself when the properties and values used in the description are defined by a shared schema or ontology.
Ontologies provide the building blocks of RDF based conceptual models by providing a formal definition of the set of concepts within a domain and the relationships between those concepts. A variety of ontology languages have been derived using RDF, currently however, the two most commonly used are RDF Schema (RDFS) and the Web Ontology Language (OWL).
RDFS introduces the notions of concepts and instances. A concept describes an entity on an abstract level with generic properties, whereas an instance is an actual representation of this concept with specific values of these properties. OWL adds more vocabulary for describing properties and classes including: relations between classes (e.g. subclassess, disjointness), cardinality, richer typing of properties and enumerated classes. RDFS and OWL are powerful applications of RDF for describing conceptual data models.
An example conceptual data model expressed in RDF/RDFS
relating artists, albums and tracksEven the necessarily very terse description of RDF above is sufficient to highlight some key differences between a conceptual model described by RDF/OWL and a relational logical model.
RDF works directly at the level of concepts, entities, attributes and relationships. The terminology used above to describe RDF corresponds directly with Wikipedia's definition of a conceptual model as a map of concepts and their relationships, describing 'things' of significance to an organization (entity classes), their characteristics (attributes) and associations between pairs of those things of significance (relationships).
Whereas in an RDF-based conceptual model the relation between two entities (the subject and object) is stated explicitly by the predicate component of a triple, in a relational logical model, the predicate is missing. Rather than triples, a relational schema in effect defines a set of 'doubles' relating pairs of entity instances, i.e. two rows from tables related by a foreign key, where the relationship indicated by the foreign key isn't stated. As well as making relationships explicit, the semantic expressivity generally of RDF and RDFS/OWL is much better than DDL. Hence a conceptual model based on the former has far richer semantic content than a logical model which must be inferred from DDL table descriptions.
RDF's use of URIs for entity identity (in practice HTTP-based URLs plus a "#this" suffix), Web-enables both the data and the schema such that representation of either become dereferencable globally, i.e. beyond traditional enterprise or application silo confines. URIs, whose scalability has been proven by the success of the Web itself, provide globally unique identifiers for entities, relationships and classes, making them 'universally grounded'. In contrast the schema described by DDL is internal to the specific DBMS hosting it, largely implicit, and in most cases accessible only within a given enterprise or specific application enclave. Similarly, a primary key identifying an individual table row, in effect acting as an entity instance ID, is not globally immutable, unique, or easily usable outside the host system. In these respects the Semantic Web is, by virtue of the design of RDF and OWL, a vehicle for very granular global information sharing (in effect down to the equivalent of the record level in a DBMS).
Linked Data is a term used to describe an HTTP based 'data access by reference' pattern that facilitates exposing, sharing, and connecting data objects (entities) on the Web via dereferenceable URIs. The original proposal by Tim Berners-Lee outlined the following:
Although some view "Linked Data" as a re-branding of the Semantic Web, the Semantic Web by another name, others view it as a stepping stone towards a full blown Semantic Web of intelligent agents and inferencing, as originally envisaged. Linked Data instead focuses on the world-wide interconnection, exchange and re-use of data, without the AI component. Starting from the W3C Semantic Web Education and Outreach group's [[http://esw.w3.org/topic/SweolG/TaskForces/CommunityProjects/LinkingOpenData][Linking Open Data community project], Linked Data has evolved from simply a concept into a vigorous community which to date has published several Open Data data-sets totaling over two billion triples.
While commentators might differ over the exact differences between the Semantic Web and Linked Data, the term "Linked Data" conveys more directly the value of the Semantic Web. What the Linked Data movement is initiating is a move from a Web linked at the document-todocument level, to one linked at the entity-to-entity level. The enabler behind this transition is RDF's ability to provide a framework for distributed, shareable conceptual models in which entities, not documents solely, are the focal point.
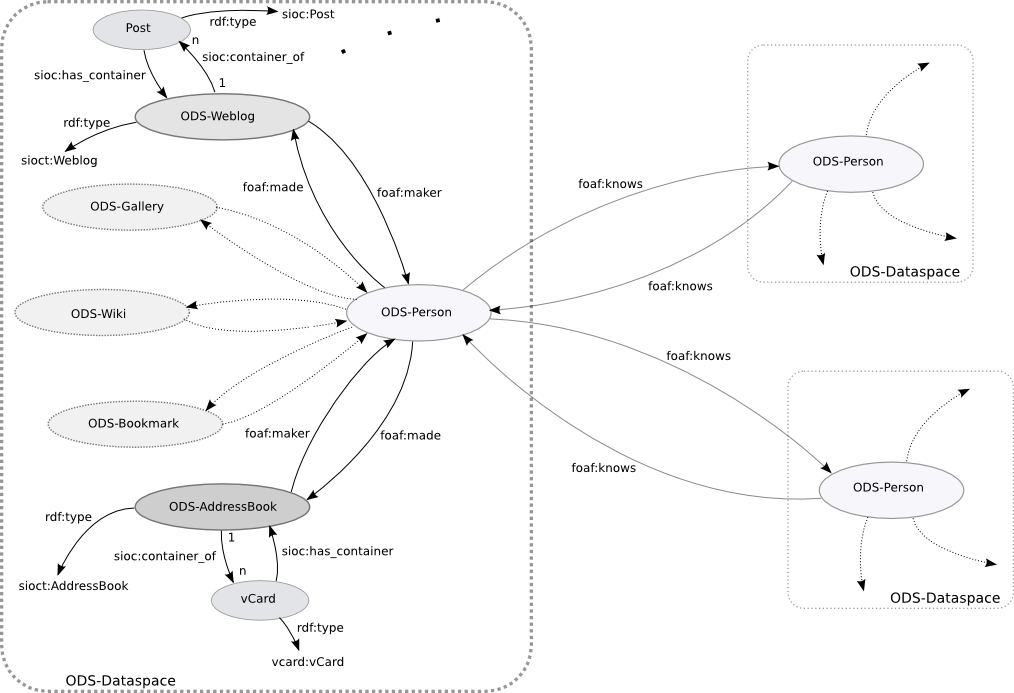 The Linked Data model changes the focus from linked
documents to linked entities
The Linked Data model changes the focus from linked
documents to linked entities
By embedding or attaching RDF metadata to HTML documents, describing the things (entities) it contains with RDF links to other related things, one can create a web of linked data which exists in parallel with the web of documents.
Indeed it could be argued that the document as a data container becomes less relevant as the underlying web of data becomes more transparent. Once any data contained in a document has been extracted and stored in an RDF store, for instance via the Virtuoso Sponger (RDF crawler), the document could in principle be discarded. Obviously this might not be desirable for an HTML document as it provides a human-readable rendition of the data, but it illustrates the change in focus from documents to data. Ultimately, the effect will be to change the Web from being a global file system to a global database.
By making the URIs identifying RDF entities dereferenceable URLs, it is possible to navigate from a data item within one data source to related data items within other sources. (How to make entity URIs dereferenceable is discussed at length in the OpenLink document Deploying Linked Data.) Moving from one entity to another is straightforward and natural - requiring just a click to dereference a resource description via its URI. OpenLink's own Linked Data client and browser extension, OpenLink Data Explorer, ably demonstrates this and other Linked Data virtues.
In the relational world, navigation between related entities is cumbersome at best. At the database level it requires SQL joins. Higher up the implementation stack, applications frequently rely on heavyweight object relational mapping layers to expose parent-child relationships as collections dereferenced through 'dot notation', e.g. In C#,
track = lennonAlbum.Tracks["Mother"]
Whereas in an HTML link, the relationship between the linking and linked-to documents is not described, the relationship between two entities in an RDF statement is described explicitly through the predicate. In effect the URI of the object entity becomes a "typed link" with the type defined by the predicate. The definition of the relationship is readily available through the ontology pointed to by the predicate URI. In logical schemas, metadata describing the relationship between two entities is not directly available.
RDF is a technology for creating self-describing Web resources, making it is possible to retrieve a Web resource without knowing beforehand anything about what it represents. Likewise, it's possible to query an RDF dataset using SPARQL without knowing anything about the data.
Logical schemas lack this flexibility. Rather than relational data being self describing, users or applications need a detailed understanding of the schema and its implied semantics to use and navigate the data. An application's knowledge of the schema is typically hard-coded into it. More general database explorer or reporting tools require that the user interpret an unfamiliar schema. Without explicit semantics, ad-hoc end-user data exploration is difficult and data prone to misinterpretation.
RDF and Linked Data, on the other hand, provide the basis for very powerful data exploration tools. Because the subject, the predicate, and often the object as well, are identified by URIs, if a user agent has no built-in knowledge of some particular RDF subject, relationship, or object, it can use the URI to retrieve the information necessary for processing or describing it. To state that it is an instance of a particular type or class, a resource can use the RDFS predicate rdfs:type, or its alias "a". The same predicate can identify a resource property and the rdfs:range predicate the property's type. e.g.
opl:Department a rdfs:Class ;
rdfs:label "Department" .
opl:dept_name a rdf:Property ;
rdfs:domain opl:Department ;
rdfs:range xsd:string ;
rdfs:label "Department name" .
opl:dept_manager a rdf:Property ;
rdfs:domain opl:Department ;
rdfs:range opl:Employee ;
rdfs:label "Department manager" .
Hence when the RDF description of an entity includes rdfs:type statements, the entity's type and the type of its properties are instantly identifiable.
When exploring a new RDF data source, through the power of SPARQL, it is easy to discover what sort of things the data source contains. The SPARQL query
select distinct ?URI ?ObjectType where {?URI a ?ObjectType}
returns all the entity classes in the current default graph or data set. Determining all the properties of a class is equally straightforward. The query
select * where { <http://my.org/resourceTypes/Department> ?property ?hasValue }
returns all the properties of the Department class. Similarly, assuming that entity Accounts is a type of Department, the query
select * where { <http://my.org/resource/Accounts> ?property ?hasValue }
returns all the properties defined by the Department class, as well as the values of those properties for the Accounts department. In this sense, RDF data is self describing. There is no need to know about traditional metadata (logical schemas) before exploring a data set.
Often it's desirable to have an integrated view of all the data available about an item or topic. In the database realm, if the data is spread over multiple databases, integrating it is problematic because of the difficultly of combining the different database schemas.
In the Semantic Web however, this type of aggregation is easy to achieve. (Here we use the term in its general sense to mean "collect into a mass or sum" rather than any formal programming or data modelling definition.) Since every Semantic Web resource has a unique URI, it is possible to establish links not just between individual items, but also between conceptual models. Whenever a model of a specific domain has been published on the Web, others are potentially able to build on it, enriching the domain knowledge or establishing cross-domain links. Linked Data aims to exploit this facility to the full.
Moreover, multiple data creators may define different URIs to describe the same thing. These descriptions may be quite different, describing different facets of the same entity, which may be a person or city for instance. Linking these descriptions together (typically using the OWL sameAs predicate) creates an aggregated view which provides a more complete picture of the item of interest and may expose facts that are not directly represented in any one source.
Microsoft's ADO.NET Data Services, which we'll refer to by its codename "Astoria", provides a framework for exposing a "pure data" service over HTTP with a REST-style programming interface. The goal of Astoria is to make data available to loosely coupled systems for querying and manipulation. It is designed for creating, retrieving, updating and deleting relational data through a uniform interface over the Web.
Astoria data services use the Entity Data Model (EDM) component of .NET's Entity Framework as the mechanism for data exposure. EDM exposes high-level conceptual data models over relational data, allowing Astoria to add semantics to a service, such as clearly defining what constitutes an "entity" for a given service or how to navigate between related entities.
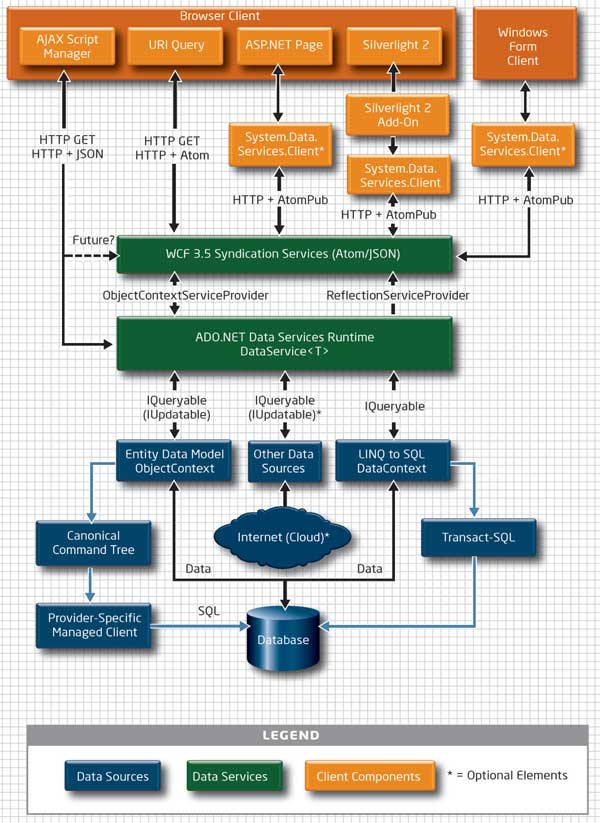
In aiming to separate data from presentation, expose data entities on the Web, and with its emphasis on conceptual models, Astoria might at first glance appear to have some similarities with Linked Data. However, it differs in many respects as highlighted by the some significant differences covered in the sections that follow.
At the current time, Astoria does not support RDF (Data Model or Serialization formats). As a result, it fails to imbibe any of its inherent benefits, many of which have been outlined in prior sections of this document.
The most obvious limitation of Astoria is its lack of platform independence. On the server side, it is targeted firmly at Windows platforms. On the client side it is conceivable that non-Windows clients could consume Astoria services output at a low level given that Astoria supports HTTP REST-style interfaces and response payload formats such as Atom, JSON and XML. But, consuming Astoria services at a higher level requires a Windows .NET client or a browser supported by Silverlight.
Astoria supports a powerful URL addressing scheme which enables clients to query, navigate collections, sort and filter through a URL, e.g.
http://myserver/data.svc/Customershttp://myserver/data.svc/Customers('ALFKI')http://myserver/data.svc/Customers('ALFKI')/OrdersHowever, although the EDM framework underpinning Astoria manifests entities to Astoria and Astoria clients, a client must nevertheless know the conceptual schema associated with the data it is handling. In order to construct the example URIs above, a client must be aware of the entity classes available and their relationships. Contrast this with the ability of SPARQL to uncover entity classes in an unknown data source via SPARQL DESCRIBE, as illustrated earlier. In short, the conceptual schema is not made available to the client, instead it is hidden on the server-side available only to the Entity Framework.
By not incorporating the RDF data model in conjunction with the openness of Web architecture, the utility of globally dereferencable identifiers is completely missing from Astoria. Thus, the ability to discovery entities and dereference representations of their descriptions (data attributes and relationship graphs) is at best confined to programming facilities specific to the .NET realm.
Within an enterprise and even more so on the Web, not all data resides in relational databases. A vast amount of useful data resides in existing unstructured and semi-structured data sources. The technologies surrounding the Semantic Web and Linked Data inherently recognize this as exemplified by the plethora of middleware tools for converting non-RDF into RDF, and the emergence of mechanisms such as RDFa and eRDF for embedding RDF statements within existing (X)HTML resources.
In contrast, Astoria is aimed exclusively at making relational data Web accessible. Coupled with the other limitations of its conceptual model described above, it cannot match the scalability and scope of the Semantic Web technologies.
In the course of discussing the ongoing evolution of the Web from a web of linked documents to a web of linked data, brief mention was made of the Virtuoso Sponger. The Sponger is a full featured RDFizer, a new class of tool for converting existing data into RDF. Because most of the data exposed on the Web to date resides in non-RDF data sources, RDFizers have a key role to play in helping to bootstrap the Linked Data web. Further, huge amounts of company data resides in relational databases. Again, tools to expose relational data as Linked Data are crucial for fueling the transition to a linked data Web. OpenLink provides this capability through its support for RDF Views.
The diagram below illustrates how Virtuoso's Sponger and RDF Views provide Linked Data clients with a bridge to a disparate range of non-RDF data sources.
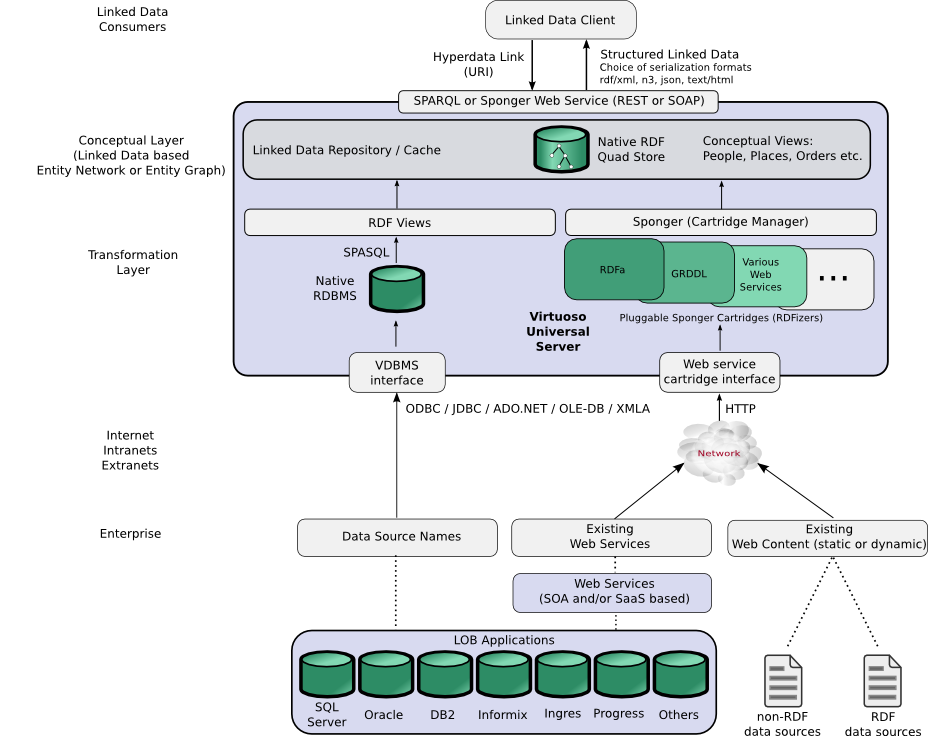 Linked data generation options using Virtuoso
Universal Server
Linked data generation options using Virtuoso
Universal Server
More importantly in the context of this document, the diagram illustrates how a conceptual layer built around Linked Data can insulate a Linked Data consumer from the details of the RDFization infrastructure and the heterogeneity of the underlying data sources.
While Microsoft's Astoria provides a Redmond vision of exposing data on the Web, it lacks of support for RDF makes it unusable as a means of bridging the Windows and Linked Data realms. How then might this be achieved? One promising project is LINQ to RDF (aka LinqToRdf) which constitutes an early effort to fill this gap. OpenLink has produced a whitepaper Exploiting the RDF-based Linked Data Web using .NET via LINQ which provides a brief overview of LinqToRdf and an example of its use to retrieve data from the MusicBrainz? music metadatabase via an OpenLink Virtuoso Quad Store. The document also illustrates the use of the Virtuoso Sponger to convert the raw MusicBrainz data to RDF on-the-fly.
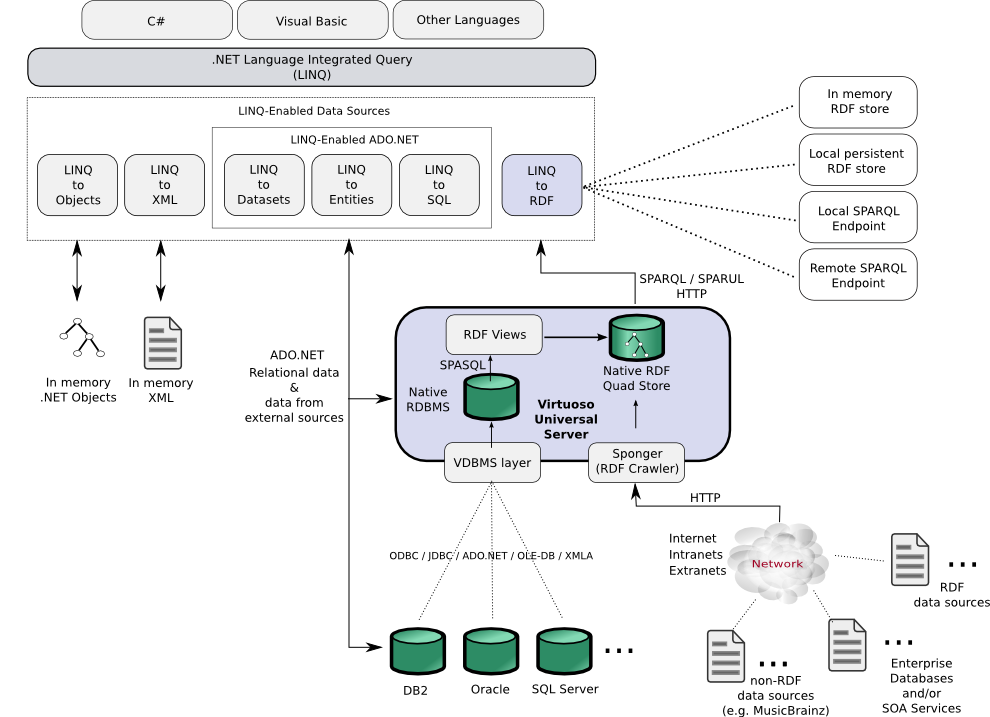 Bridging from LINQ to Linked Data using LinqToRdf
Bridging from LINQ to Linked Data using LinqToRdf
For further details of RDF Views, the Sponger and how to deploy Linked Data, please refer to the OpenLink Virtuoso white papers library and in particular the following documents: